Zadanie 1 (EDA)
To zadanie zostało wykonane przez jedną osobę (Łukasz Mielewczyk). Wykonane zostały różne zapytania w bazach danych posgreSQL oraz elasticsearch. Pokazano w jakim czasie zostały wykonane oraz ile zasobów zużywały poszczególne czynności. Dodano podsumowanie wszystkiego. Został również przedstawiony opis danych oraz instrukcja co i jak zostało wykonane.
Informacje o danych
Dane zawierają najnowsze (luty 2017 r.) dane z katalogu pocztowego służb zdrowia w Wielkiej Brytanii. Źródło. Rozmiar: 2 GB Ilość: 2593752
Instalacja i konfiguracja oprogramowania
postgreSQL
Do rozwiązania zadania użyto bazy postgreSQL. Należy ją pobrać ze strony i zainstalować. Podczas instalacji możliwe, że będzie konieczne podanie hasła domyślnego użytkownika postgres.
jdk
Aby uruchomić bazę elasticsearch potrzebny jest najnowyszy jdk, który jest możliwy do sciągniecia ze strony oraz należy to zainstalować. Następnie należy upewnić się czy zmienne środowiskowe są odpowiednio skonfigurowane.
python
Python będzie potrzebny do uruchomienia skryptów. Pobierz ze strony najnowaszą wesję, następnie należy zainstalować.
PostgreSQL
import danych
Pobierz dane. Pobierz skrypt oraz przenieś go do folderu do którego zostały pobrane dane. Następnie należy uruchomić skrypt, który usunie znaki nie kodowane w windows-1250, polecenie w cmd:
py s1.py
pgfutter --pass "[hasło]" --table "test" csv map.csv
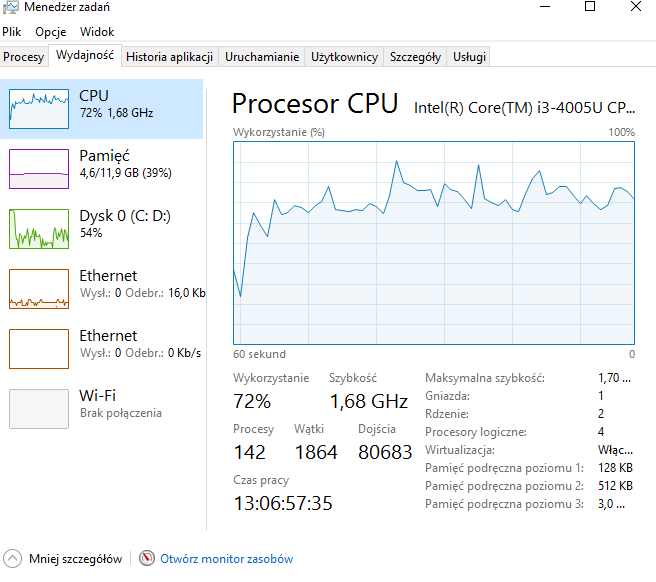
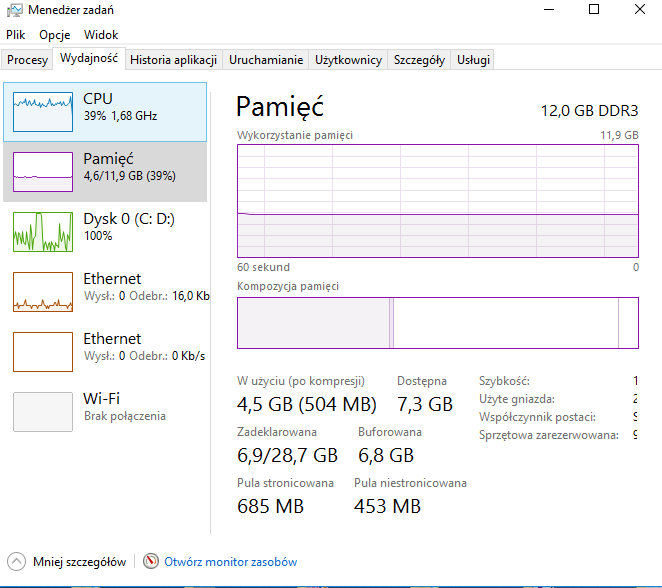
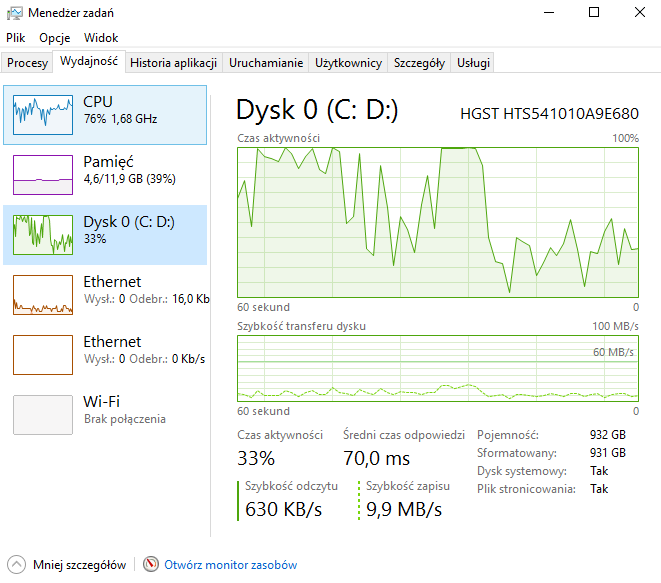

przykładowy rekord
Należy uruchamić serwer, aby to zrobić, należy przemieścić się do pliku binarnego posgreSQL'a, polecenie w konsoli cmd:
cd [ścieżka gdzie jest zainstalowany postgreSQL]\PostgreSQL\9.6\bin
psql -U postgres
Następnie aby wyświetlić przykładową daną należy wydać polecenie:
select * from import.test limit 1;

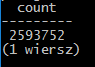
ilość danych
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony. Jeśli nie: przeczytaj jak to zrobić. Aby sprawdzić ile danych zostało zaimportowanych, należy wydać polecenie:
select count(*) from import.test;
usuwanie danych
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony. Jeśli nie: przeczytaj jak to zrobić. Niektóre kolumny zawierają puste pola np. klumny ze wspórzędnymi x oraz y, tym razem możemy usunąć te dane, polecenie:
delete from import.test where x='' and y='';
wyświetlenie danych
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony. Jeśli nie: przeczytaj jak to zrobić. Aby wykonać wyświetlenie danych takich danych gdzie ur01ind jest równe 1, polecenie:
select * from import.test where ur01ind='1';
Elasticsearch
import danych
Pobierz dane. Pobierz skrypt oraz przenieś go do folderu gdzie pobrane są dane. Następnie uruchamiamy skrypt który usuwa pierwszy wiersz (nazwy kolumn) oraz zapisuje do pliku map.csv polecenie w cmd:
py s2.py
copy [ścieżka gdzie pobrano curl]\curl\src\curl.exe [ścieżka w której ]\curl.exe
curl -XPUT http://localhost:9200/test -d "{\"mappings\": {\"place\": {\"properties\": {\"x\": {\"type\": \"string\"}, \"y\": {\"type\": \"string\"}, \"objectid\": {\"type\": \"integer\"},\"pcd2\": {\"type\": \"string\"},\"pcds\": {\"type\": \"string\"},\"dointr\": {\"type\": \"string\"},\"oseast100m\": {\"type\": \"string\"},\"osnrth100m\": {\"type\": \"string\"},\"oscty\": {\"type\": \"string\"},\"odslaua\": {\"type\": \"string\"},\"oslaua\": {\"type\": \"string\"},\"osward\": {\"type\": \"string\"},\"usertype\": {\"type\": \"string\"},\"osgrdind\": {\"type\": \"string\"},\"ctry\": {\"type\": \"string\"},\"oshlthau\": {\"type\": \"string\"},\"gor\": {\"type\": \"string\"},\"oldha\": {\"type\": \"string\"},\"nhscr\": {\"type\": \"string\"},\"ccg\": {\"type\": \"string\"},\"psed\": {\"type\": \"string\"},\"cened\": {\"type\": \"string\"},\"edind\": {\"type\": \"string\"},\"ward98\": {\"type\": \"string\"},\"oa01\": {\"type\": \"string\"},\"nhsrg\": {\"type\": \"string\"},\"hro\": {\"type\": \"string\"},\"lsoa01\": {\"type\": \"string\"},\"ur01ind\": {\"type\": \"string\"},\"msoa01\": {\"type\": \"string\"},\"cannet\": {\"type\": \"string\"},\"scn\": {\"type\": \"string\"},\"oshaprev\": {\"type\": \"string\"},\"oldpct\": {\"type\": \"string\"},\"oldhro\": {\"type\": \"string\"},\"pcon\": {\"type\": \"string\"},\"canreg\": {\"type\": \"string\"},\"pct\": {\"type\": \"string\"},\"oseast1m\": {\"type\": \"string\"},\"osnrth1m\": {\"type\": \"string\"},\"oa11\": {\"type\": \"string\"},\"lsoa11\": {\"type\": \"string\"},\"msoa11\": {\"type\": \"string\"}}}}}"
cd [ścieżka gdzie pobrano logstash]\logstash-5.3.0\bin
copy [ścieżka gdzie pobrano plik konfiguracyjny]\btc.conf [ścieżka gdzie pobrano logstash]\logstash-5.3.0\bin
copy [ścieżka gdzie znajduje się plik map]\map.csv C:\
logstash -f btc.conf
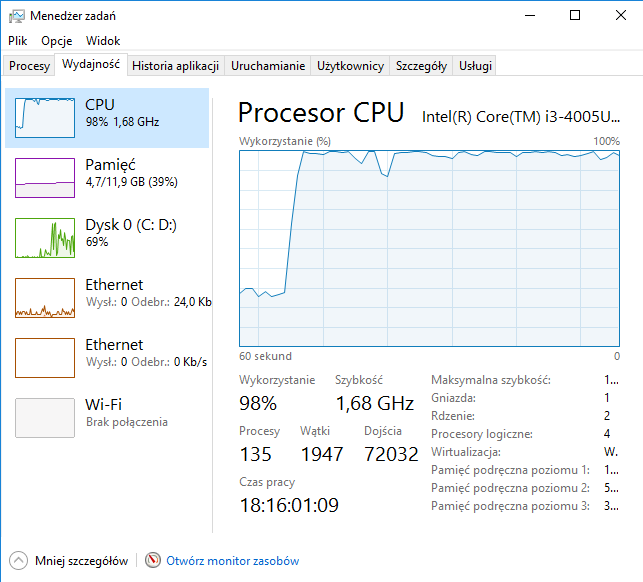
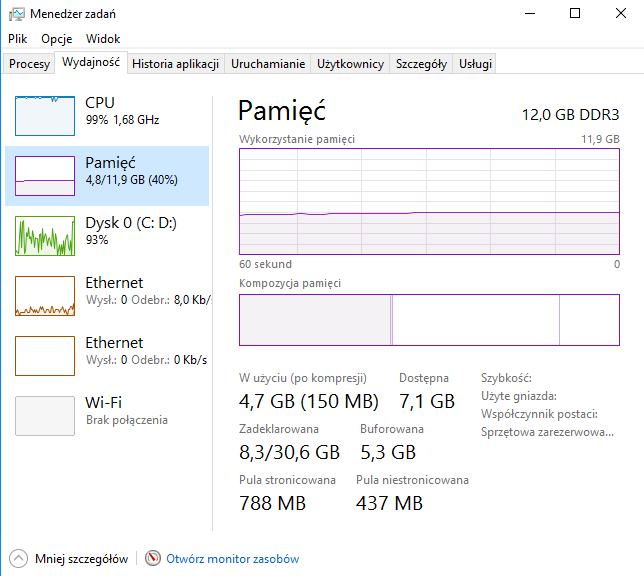
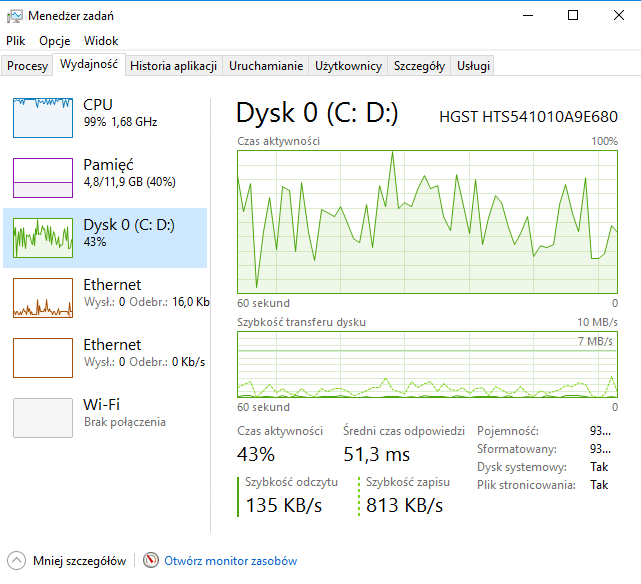
przykładowy rekord
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony oraz wszystko poprawnie skonfigurowanie. Jeśli nie: przeczytaj jak to zrobić. Po zaimportowaniu danych należy wydać polecenie:
curl -s "http://localhost:9200/test/_search?size=1&pretty=1&filter_path=hits.hits._source"
{
"hits" : {
"hits" : [
{
"_source" : {
"doterm" : "200604",
"odslaua" : "416",
"oshaprev" : "Q28",
"ccg" : "05J",
"ward98" : "47UBFQ",
"oseast1m" : "396231",
"lsoa01" : "E01032130",
"gor" : "E12000005",
"osgrdind" : "1",
"msoa11" : "E02006708",
"path" : "C:/map.csv",
"oldhro" : "Y42",
"oscty" : "E10000034",
"osward" : "E05009825",
"nhscr" : "Y55",
"host" : "DESKTOP-GKM51PJ",
"osnrth100m" : "02690",
"dointr" : "200512",
"oseast100m" : "3962",
"scn" : "N56",
"hro" : "Y51",
"pcon" : "E14000605",
"usertype" : "1",
"lsoa11" : "E01032130",
"oldha" : "QEN",
"pcd2" : "B60 9BG",
"cannet" : "N12",
"osnrth1m" : "0269016",
"ur01ind" : "5",
"canreg" : "Y1201",
"oshlthau" : "Q34",
"oa11" : "E00172228",
"cened" : "JSFQ04",
"oldpct" : "5MR",
"nhsrg" : "Q77",
"oslaua" : "E07000234",
"ctry" : "E92000001",
"psed" : "25UBFQ04",
"@version" : "1",
"edind" : "1",
"oa01" : "E00163889",
"pct" : "5PL",
"message" : "-2.056710443739379,52.319246511816203,82772,B60 9BG,B60 9BG,200512,200604,3962,02690,E10000034,416,E07000234,E05009825,1,1,E92000001,Q34,E12000005,QEN,Y55,05J,25UBFQ04,JSFQ04,1,47UBFQ,E00163889,Q77,Y51,E01032130,5,E02006708,N12,N56,Q28,5MR,Y42,E14000605,Y1201,5PL,396231,0269016,E00172228,E01032130,E02006708",
"msoa01" : "E02006708",
"@timestamp" : "2017-04-08T08:00:34.838Z",
"pcds" : "B60 9BG",
"x" : "-2.056710443739379",
"y" : "52.319246511816203",
"objectid" : "82772"
}
}
]
}
}
ilość danych
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony oraz wszystko poprawnie skonfigurowanie. Jeśli nie: przeczytaj jak to zrobić. Aby sprawdzić ile danych zostało zaimportowanych należy wydać polecenie:
curl -XGET localhost:9200/test/_count
{"count":2593752,"_shards":{"total":5,"successful":5,"failed":0}}
usuwanie danych
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony oraz wszystko poprawnie skonfigurowanie. Jeśli nie: przeczytaj jak to zrobić. Przed wykonaniem czynności upewnij się czy serwer oraz wszystko poprawnie skonfigurowanie jest uruchiomony. Jeśli nie: przeczytaj jak to zrobić. Można usunąć wszystkie dane gdzie gor = N99999999, polecenie:
curl -XDELETE "http://localhost:9200/test?q=gor:'N99999999'&filter_path=hits.hits._source"
wyświetlenie danych
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony oraz wszystko poprawnie skonfigurowanie. Jeśli nie: przeczytaj jak to zrobić. Następnie można wykonać wyświetlenie danych takich danych gdzie edind jest równe 9, polecenie:
curl -s "http://localhost:9200/test/_search?pretty=true&q=edind:'9'&filter_path=hits.hits._source
Podsumowanie
Tabela przedstawia podsumowanie.| Nazwa | PostgreSQL | Elasticsearch | ||||||
|---|---|---|---|---|---|---|---|---|
| czas | CPU | Pamięć | Dysk | czas | CPU | Pamięć | Dysk | |
| Import danych | 2 min. 35 sek. | 70% | 40% | 100% | 2 godz. 30 min. | 100% | 40% | 70% |
| Przykładowy rekord | 1 sek. | 30% | 30% | 0% | 1 sek. | 30% | 30% | 0% |
| Ilość danych | 5 sek. | 30% | 30% | 0% | 1 sek. | 30% | 30% | 0% |
| Usuwanie danych | 5 sek. | 30% | 30% | 0% | 1 sek. | 30% | 30% | 0% |
| Wyświtlenie danych | 10 sek. | 30% | 30% | 0% | 1 sek. | 30% | 30% | 0% |