Zadanie GEO
To zadanie zostało wykonane przez jedną osobę (Łukasz Mielewczyk). Wykonane zostały zapytania geodezyjne w bazach danych posgreSQL oraz elasticsearch. Pokazano w jakim czasie zostały wykonane oraz ile zasobów zużywały poszczególne czynności. Został również przedstawiony opis danych oraz instrukcja co i jak zostało wykonane.
Informacje o danych
Dane zawierają najnowsze (luty 2017 r.) dane z katalogu pocztowego służb zdrowia w Wielkiej Brytanii. Źródło. Rozmiar: 2 GB Ilość: 2593752
Instalacja i konfiguracja oprogramowania
postgreSQL
Do rozwiązania zadania użyto bazy postgreSQL. Należy ją pobrać ze strony i zainstalować. Podczas instalacji możliwe, że będzie konieczne podanie hasła domyślnego użytkownika postgres.
jdk
Aby uruchomić bazę elasticsearch potrzebny jest najnowyszy jdk, który jest możliwy do sciągniecia ze strony oraz należy to zainstalować. Następnie należy upewnić się czy zmienne środowiskowe są odpowiednio skonfigurowane.
jq
Narzędzie jq służy do przekształcenia danych w taki sposób, aby otrzymać pola które nas interesują. Aby zainstalować jq wstępnie trzeba zaisntalować framework Chocolatey. Następnie należy uruchamić konsolę cmd z uprawnieniami administratora oraz wydać polecenie:
@powershell -NoProfile -ExecutionPolicy Bypass -Command "iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))" && SET "PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin"
chocolatey install jq
python
Python będzie potrzebny do uruchomienia skryptów. Pobierz ze strony najnowaszą wesję, następnie należy zainstalować.
PostgreSQL
utworzenie tabeli
Aby uruchomić serwer, należy przemieścić się do pliku binarnego posgreSQL'a, polecenie w konsoli cmd:
cd [ścieżka gdzie jest zainstalowany postgreSQL]\PostgreSQL\9.6\bin
psql -U postgres
create table import.test(
x double precision,
y double precision,
objectid integer primary key,
pcd2 varchar,
pcds varchar,
dointr varchar,
doterm varchar,
oseast100m varchar,
osnrth100m varchar,
oscty varchar,
odslaua varchar,
oslaua varchar,
osward varchar,
usertype varchar,
osgrdind varchar,
ctry varchar,
oshlthau varchar,
gor varchar,
oldha varchar,
nhscr varchar,
ccg varchar,
psed varchar,
cened varchar,
edind varchar,
ward98 varchar,
oa01 varchar,
nhsrg varchar,
hro varchar,
lsoa01 varchar,
ur01ind varchar,
msoa01 varchar,
cannet varchar,
scn varchar,
oshaprev varchar,
oldpct varchar,
oldhro varchar,
pcon varchar,
canreg varchar,
pct varchar,
oseast1m varchar,
osnrth1m varchar,
oa11 varchar,
lsoa11 varchar,
msoa11 varchar
);
\q
import danych
Przed wykonaniem czynności upewnij się czy dane zostały przekształcone. Jeśli nie: przeczytaj jak to zrobić. Pobierz dane. Pobierz skrypt oraz przenieś go do folderu gdzie pobrane są dane. Następnie należy uruchomić skrypt, który usunie znaki nie kodowane w windows-1250, polecenie w cmd:
py s1.py
pgfutter --pass "[hasło]" --table "test" csv map.csv
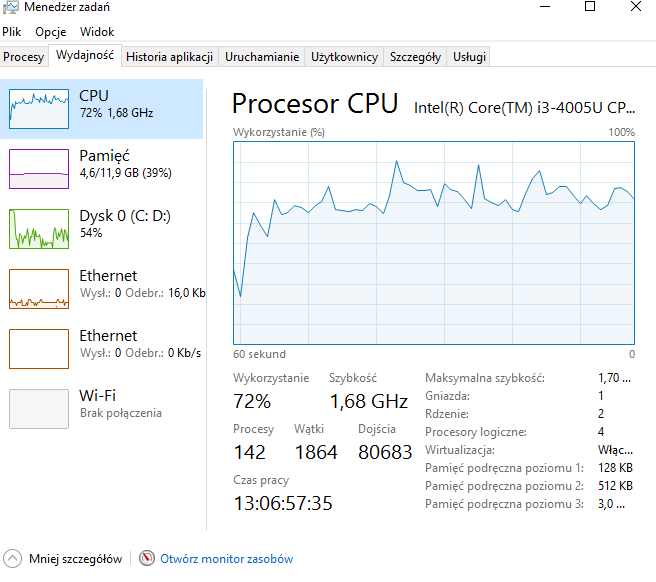
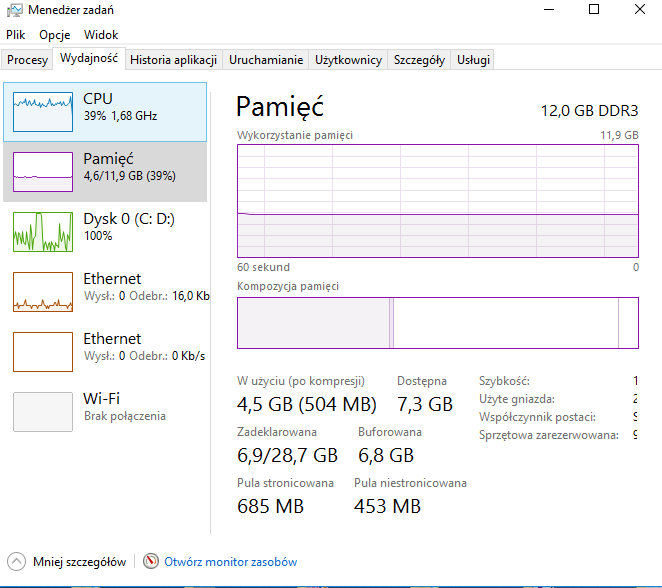
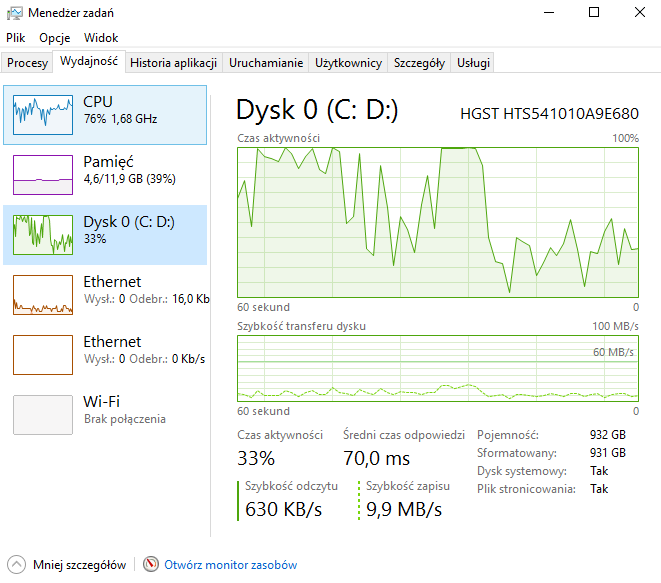

przykładowy rekord
Ponowanie należy uruchomić serwer. Przypomnenie, aby to zrobić należy przemieścić się do pliku binarnego posgreSQL'a, polecenie w konsoli cmd:
cd [ścieżka gdzie jest zainstalowany postgreSQL]\PostgreSQL\9.6\bin
psql -U postgres
Następnie aby wyświetlić przykładową daną należy wydać polecenie:
select * from import.test limit 1;

zapytania geodezyjne
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony. Jeśli nie: przeczytaj jak to zrobić. Aby korzystać z zapytań geodezyjnych należy pobrać ze strony PostGis. Po czym zmienić nazwy kolumn x na longitude
alter table import.test rename x to longitude;
alter table import.test rename y to latitude;
select * from import.test where ST_MakeEnvelope(-2.1, 57.15, -2.11, 57.14, -2.12, 57.16 4326);
Elasticsearch
przekształcenie danych
Pobierz dane. Należy usunąć zbędne pola (zostawić dane properties oraz przenieść do niego zaokrąglone dane geograficzne pod nazwą location), aby móc na nich odpowiednio operować. Zaokrąglenia są konieczne, aby zapytania w elasticsearch działały poprawnie. Plik z danymi, wymaga zmiany nazwy gdyż nie może zawierać znaków takich jak: _. Można zamienić nazwę na map.geojson. W w/w pliku interesujące pole to features, aby je przekształcić w cmd należy wydać polecenie:
jq ".features[] | (.geometry.coordinates | map( .*1000|floor|./1000)) as $l | .properties |= .+ {location: $l} | .properties" map.geojson > mapPom.geojson
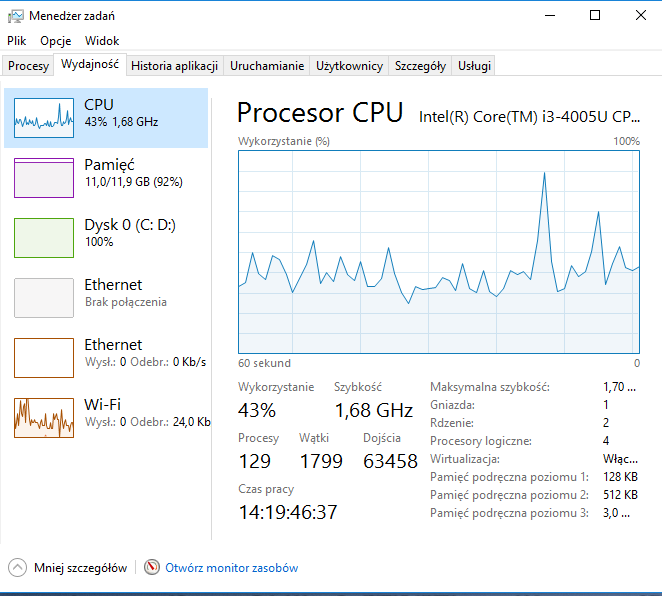
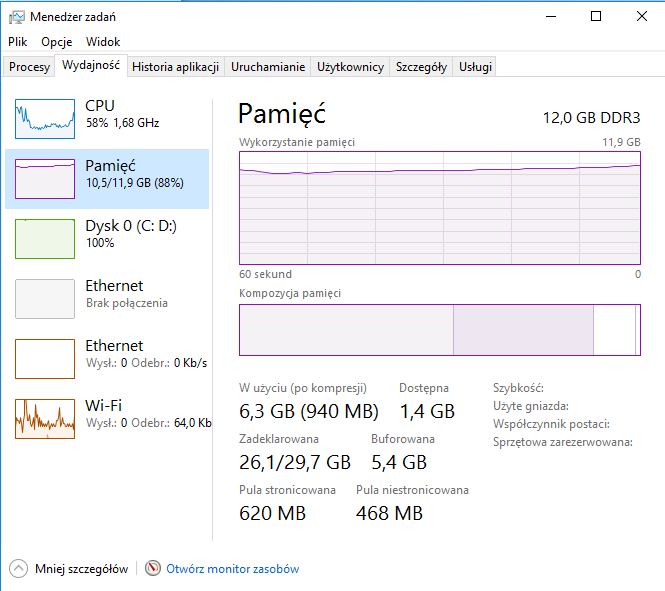
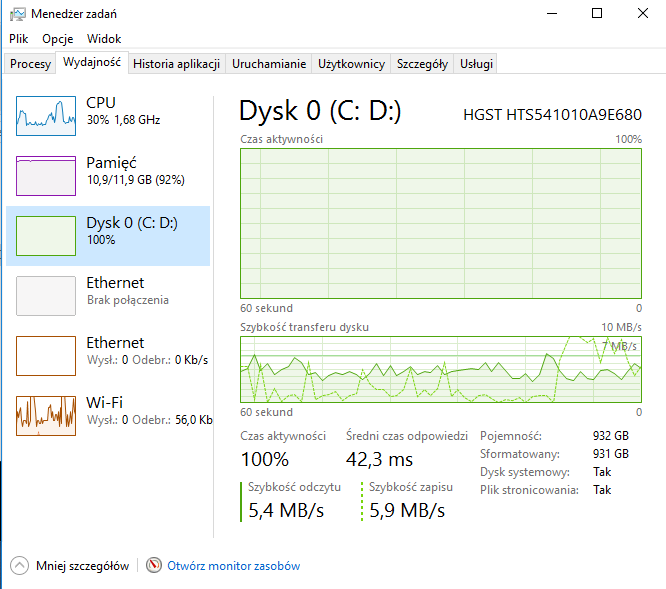
< mapPom.geojson jq --compact-output "{ \"index\": { \"_type\": \"test\" } }, ." > mapPom.bulk
import danych
Przed wykonaniem czynności upewnij się czy dane zostały przekształcone, serwer oraz wszystko poprawnie skonfigurowanie jest uruchiomony. Jeśli nie: przeczytaj jak to zrobić. Pobierz ze strony elasticsearch. Następnie aby uruchomić serwer wykonujemy polecenie w konsoli cmd:
[ścieżka gdzie pobrano elasticsearch]\elasticsearch-5.3.0\bin\elasticsearch.bat
copy [ścieżka gdzie pobrano curl]\curl\src\curl.exe [ścieżka w której ]\curl.exe
curl -XPUT http://localhost:9200/test -d "{\"mappings\": {\"place\": {\"properties\": {\"objectid\": {\"type\": \"integer\"},\"pcd2\": {\"type\": \"string\"},\"pcds\": {\"type\": \"string\"},\"dointr\": {\"type\": \"string\"},\"oseast100m\": {\"type\": \"string\"},\"osnrth100m\": {\"type\": \"string\"},\"oscty\": {\"type\": \"string\"},\"odslaua\": {\"type\": \"string\"},\"oslaua\": {\"type\": \"string\"},\"osward\": {\"type\": \"string\"},\"usertype\": {\"type\": \"string\"},\"osgrdind\": {\"type\": \"string\"},\"ctry\": {\"type\": \"string\"},\"oshlthau\": {\"type\": \"string\"},\"gor\": {\"type\": \"string\"},\"oldha\": {\"type\": \"string\"},\"nhscr\": {\"type\": \"string\"},\"ccg\": {\"type\": \"string\"},\"psed\": {\"type\": \"string\"},\"cened\": {\"type\": \"string\"},\"edind\": {\"type\": \"string\"},\"ward98\": {\"type\": \"string\"},\"oa01\": {\"type\": \"string\"},\"nhsrg\": {\"type\": \"string\"},\"hro\": {\"type\": \"string\"},\"lsoa01\": {\"type\": \"string\"},\"ur01ind\": {\"type\": \"string\"},\"msoa01\": {\"type\": \"string\"},\"cannet\": {\"type\": \"string\"},\"scn\": {\"type\": \"string\"},\"oshaprev\": {\"type\": \"string\"},\"oldpct\": {\"type\": \"string\"},\"oldhro\": {\"type\": \"string\"},\"pcon\": {\"type\": \"string\"},\"canreg\": {\"type\": \"string\"},\"pct\": {\"type\": \"string\"},\"oseast1m\": {\"type\": \"string\"},\"osnrth1m\": {\"type\": \"string\"},\"oa11\": {\"type\": \"string\"},\"lsoa11\": {\"type\": \"string\"},\"msoa11\": {\"type\": \"string\"},\"location\": {\"type\": \"geo_point\" }}}}}"
curl -XPOST localhost:9200/test/_bulk --data-binary @mapPom.bulk
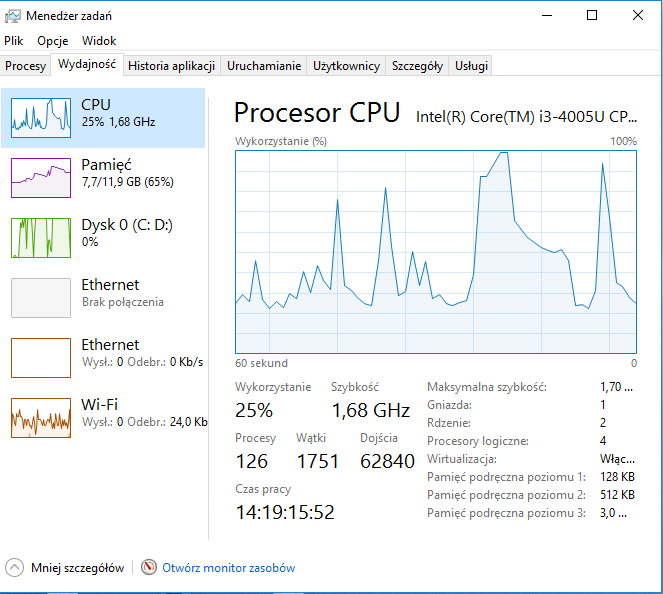
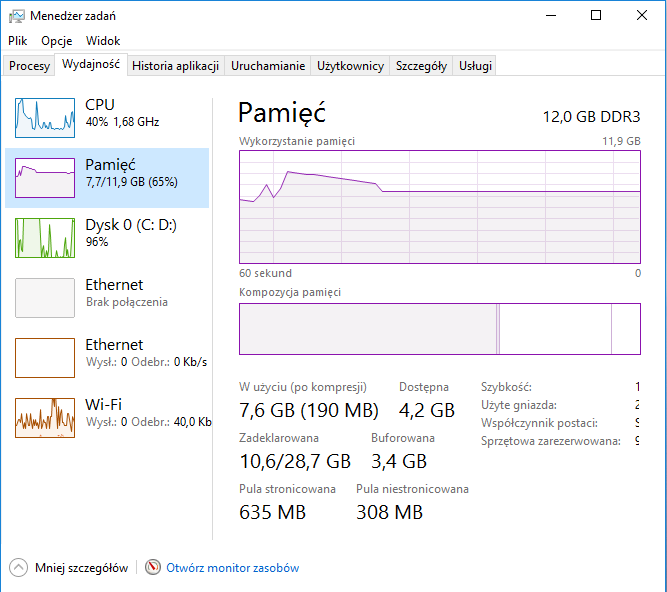
curl -XGET localhost:9200/test/_count
{"count":2593752,"_shards":{"total":5,"successful":5,"failed":0}}
przykładowy rekord
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony oraz wszystko poprawnie skonfigurowanie. Jeśli nie: przeczytaj jak to zrobić. Po zaimportowaniu danych należy wydać polecenie:
curl -s "http://localhost:9200/test/_search?size=1&pretty=1" | jq .hits.hits[].\"_source\"
{
"objectid": 2005,
"pcd2": "AB1 7FS",
"pcds": "AB1 7FS",
"dointr": "199205",
"doterm": "199606",
"oseast100m": "3912",
"osnrth100m": "08033",
"oscty": "S99999999",
"odslaua": "S92",
"oslaua": "S12000033",
"osward": "S13002486",
"usertype": "0",
"osgrdind": "1",
"ctry": "S92000003",
"oshlthau": "SN9",
"gor": "S99999999",
"oldha": "SN9",
"nhscr": "S92",
"ccg": "012",
"psed": "99ZZ0099",
"cened": "ZZ0099",
"edind": "9",
"ward98": "00QA39",
"oa01": "S00001586",
"nhsrg": "S92",
"hro": "S00",
"lsoa01": "S01000039",
"ur01ind": "1",
"msoa01": "S02000008",
"cannet": "Z99",
"scn": "Z99",
"oshaprev": "SN9",
"oldpct": "X98",
"oldhro": "S00",
"pcon": "S14000002",
"canreg": "Z9999",
"pct": "012",
"oseast1m": "391250",
"osnrth1m": "0803360",
"oa11": "S00090643",
"lsoa11": "S01006526",
"msoa11": "S02001239",
"location": [
-2.134,
57.123
]
}
polecenia geodezyjne (mapki)
Przed wykonaniem czynności upewnij się czy serwer jest uruchiomony oraz wszystko poprawnie skonfigurowanie. Jeśli nie: przeczytaj jak to zrobić. Pierwsze 2000 danych zobrazowanych, polecenie:
curl -s "http://localhost:9200/test/test/_search?size=2000&pretty=1" | jq .hits.hits[].\"_source\" | jq "{type:\"Feature\", properties: {objectid, pcd2, pcds, dointr, doterm, oseast100m, osnrth100m,oscty, odslaua, oslaua, osward, usertype, osgrdind, ctry, oshlthau, gor, oldha, nhscr, ccg, psed, cened ,edind, ward98, oa01, nhsrg, hro, lsoa01, ur01ind, msoa01, cannet, scn, oshaprev, oldpct, oldhro, pcon, canreg, pct, oseast1m, osnrth1m, oa11, lsoa11,msoa11,}, geometry: {type:\"Point\", coordinates: .location}}" | jq --slurp . | jq {type:\"FeatureCollection\",features:.} > map1.geojson
curl -XGET localhost:9200/test/_search?pretty -d "{\"size\":500,\"query\":{\"bool\":{\"must\":{\"match_all\":{}}, \"filter\":{\"geo_distance\":{\"distance\":\"1000km\",\"location\":{\"lat\":57.149651,\"lon\":-2.099075}}}}}}" | jq .hits.hits[]._source | jq "{type:\"Feature\", properties: {objectid, pcd2, pcds, dointr, doterm, oseast100m, osnrth100m,oscty, odslaua, oslaua, osward, usertype, osgrdind, ctry, oshlthau, gor, oldha, nhscr, ccg, psed, cened ,edind, ward98, oa01, nhsrg, hro, lsoa01, ur01ind, msoa01, cannet, scn, oshaprev, oldpct, oldhro, pcon, canreg, pct, oseast1m, osnrth1m, oa11, lsoa11,msoa11,}, geometry: {type:\"Point\", coordinates: .location}}" | jq --slurp . | jq {type:\"FeatureCollection\",features:.} > map2.geojson
curl -XGET localhost:9200/test/_search?pretty -d "{\"size\":100,\"query\":{\"bool\":{\"must\":{\"match_all\":{}}, \"filter\":{\"geo_polygon\":{\"location\":{\"points\":[[-2.1, 57.15],[-2.11,57.14],[-2.12,57.16]]}}}}}}" | jq .hits.hits[]._source | jq "{type:\"Feature\", properties: {objectid, pcd2, pcds, dointr, doterm, oseast100m, osnrth100m,oscty, odslaua, oslaua, osward, usertype, osgrdind, ctry, oshlthau, gor, oldha, nhscr, ccg, psed, cened ,edind, ward98, oa01, nhsrg, hro, lsoa01, ur01ind, msoa01, cannet, scn, oshaprev, oldpct, oldhro, pcon, canreg, pct, oseast1m, osnrth1m, oa11, lsoa11,msoa11,}, geometry: {type:\"Point\", coordinates: .location}}" | jq --slurp . | jq {type:\"FeatureCollection\",features:.} > map3.geojson